Using RAG with Superexpert.AI
Superexpert.AI supports powerful Retrieval-Augmented Generation (RAG) functionality to enhance your AI agents’ ability to retrieve and utilize information from large files and databases effectively.
Why Use RAG?
Retrieval-Augmented Generation (RAG) allows your AI agents to access information from extensive documents and databases that exceed the typical context window limits of AI models. Unlike file attachments, which load the entire file into the agent’s context, RAG intelligently retrieves relevant text chunks based on the similarity to the user’s queries.
When you use RAG:
- Files are chunked into smaller, manageable pieces.
- Each chunk is converted into vector embeddings and stored in a database.
- User queries are similarly converted into embeddings and matched against these stored chunks.
Ideal Use Cases for RAG:
- Quickly searching product documentation for customer support.
- Providing accurate, context-specific answers from large sets of academic articles or research papers.
- Accessing detailed historical or factual data that would otherwise exceed standard context limitations.
Walkthrough: Setting Up and Using RAG
In this walkthrough, we’ll upload and use a file named titanic.json, which contains detailed passenger data from the Titanic.
Step 1: Create a New Corpus
- From the main navigation menu, click Corpora.
- If no corpus exists, you will automatically navigate to the New Corpus page. Otherwise, click New Corpus.
- Enter a descriptive name and optional description for your corpus (e.g., “Titanic Passenger Data”).
Step 2: Upload Files to Your Corpus
You have two methods:
Method 1: Using the Web Interface
- Click Choose File to select your titanic.json file.
- Specify the Chunk Size (recommended: 100 tokens for detailed accuracy).
- Set the Chunk Overlap percentage (recommended: 15%).
- Click Upload.
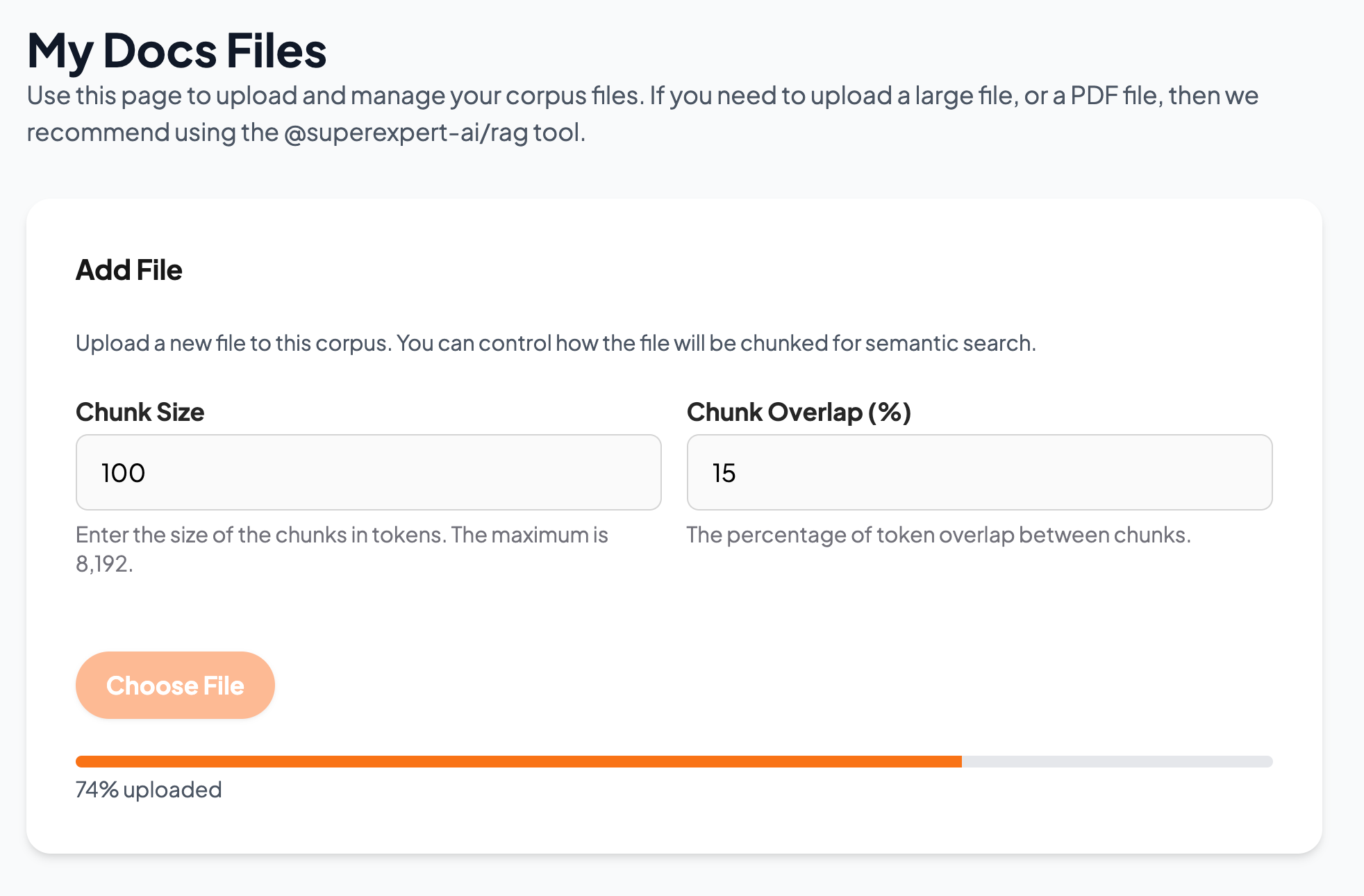 Figure 1: Uploading files with the web interface.
Figure 1: Uploading files with the web interface.
Method 2: Using the CLI Tool
- Open your terminal and run:
npx @superexpert-ai/rag init - Executing the tool with
initgenerates a rag.config.js file. Enter your configuration
settings in rag.config.js and execute the following command to chunk and upload your files:npx @superexpert-ai/rag run
The CLI tool reliably handles large files, multiple uploads, and both text and PDF files.
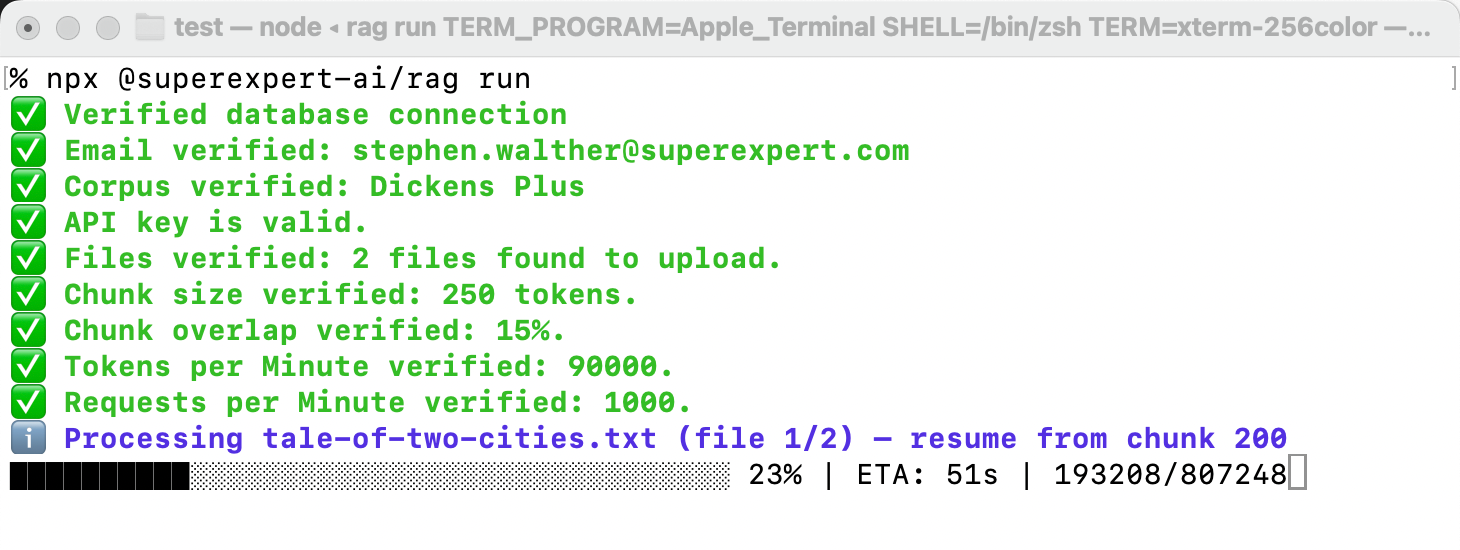 Figure 2: Uploading files with the RAG tool.
Figure 2: Uploading files with the RAG tool.
RAG Tool: For details on using the RAG tool, visit @superexpert-ai/rag.
Step 3: Test Your Corpus
- Navigate to the Corpora page.
- Click the Test button next to your corpus.
- Enter a Limit for the number of returned matches and a Similarity Threshold (higher thresholds yield more precise results).
- Enter test queries such as:
- “How old was Flynn?”
- “What cabin was Mrs Nye in?”
- “How old was Bertha?”
- Click Search to view retrieved matches.
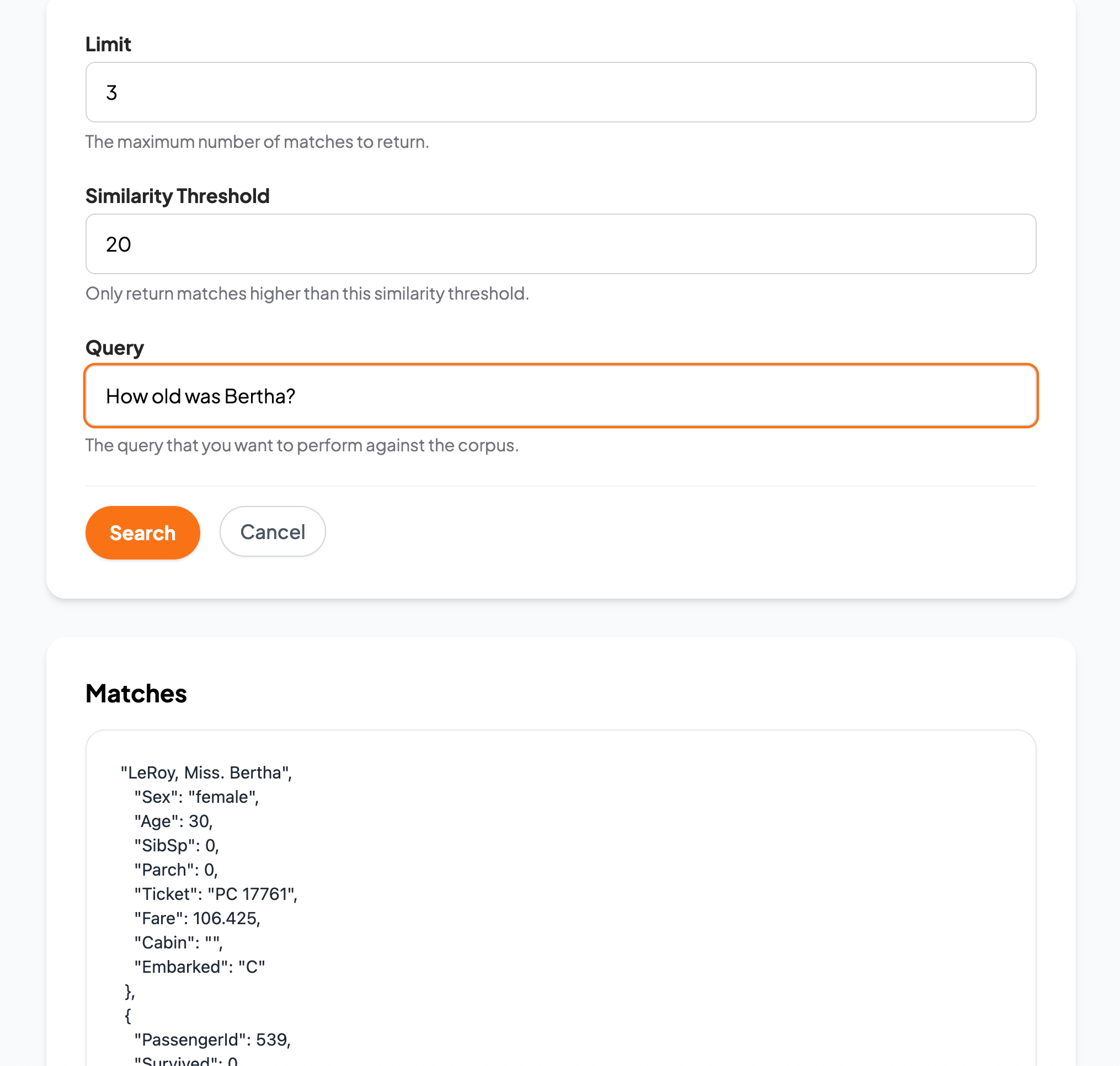 Figure 3: Testing your corpus.
Figure 3: Testing your corpus.
Step 4: Use RAG in a Chat Interface
- From the main navigation menu, select Agents.
- Click Tasks next to your chosen Agent.
- Expand the Context Data panel.
- Select your corpus and configure Limit and Similarity Threshold for real-time retrieval during chat.
- Begin a conversation by navigating to Agents > clicking Chat next to the agent.
Similarity Thresholds: We recommend that you experiment with different Similarity Thresholds. Lower values will yield more matches.
As you chat, your agent dynamically fetches relevant information from your corpus based on your messages, significantly enhancing interaction quality and accuracy.
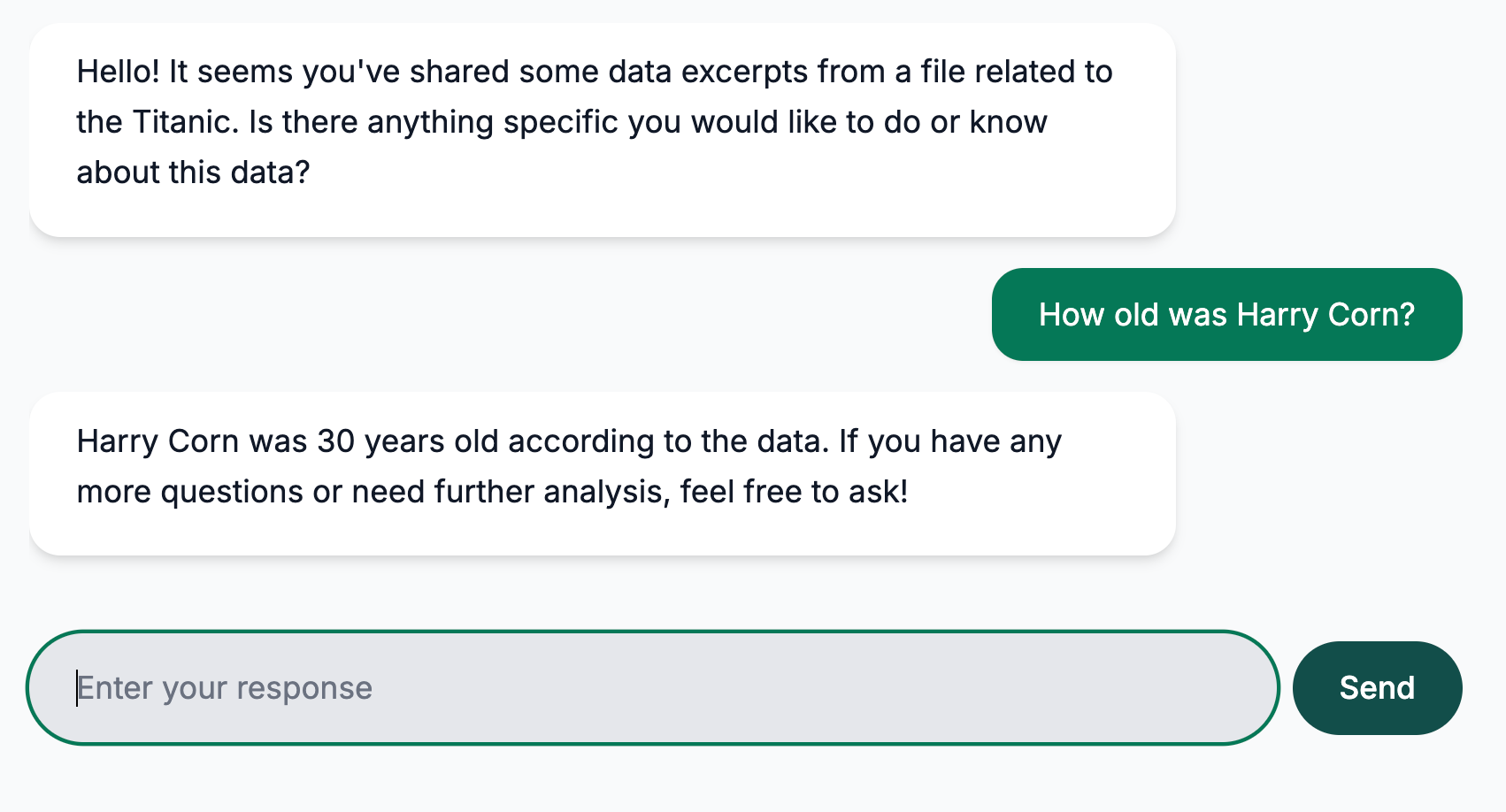 Figure 4: Using RAG with your agent.
Figure 4: Using RAG with your agent.
Technical Background
Superexpert.AI uses PostgreSQL and pgvector to efficiently store and query vector embeddings, ensuring fast and reliable RAG operations.